Descriptive vs. Inferential Statistics: What’s the Difference?
When it comes to statistic analysis, there are two classifications: descriptive statistics and inferential statistics. In a nutshell, descriptive statistics intend to describe a big hunk of data with summary charts and tables, but do not attempt to draw conclusions about the population from which the sample was taken. You are simply summarizing the data you have with pretty charts and graphs–kind of like telling someone the key points of a book (executive summary) as opposed to just handing them a thick book (raw data).
Conversely, with inferential statistics, you are testing a hypothesis and drawing conclusions about a population, based on your sample. In this case, you are going to run into fancy sounding concepts like ANOVA, T-Test, Chi-Squared, confidence interval, regression, etc., but we’ll save those for another day.

To understand the simple difference between descriptive and inferential statistics, all you need to remember is that descriptive statistics summarize your current dataset and inferential statistics aim to draw conclusions about an additional population outside of your dataset.
Perhaps these concepts are most easily explained with some examples…
Descriptive Statistics
Let’s say you’ve administered a survey to 35 people about their favorite ice cream flavors. You’ve got a bunch of data plugged into your spreadsheet and now it is time to share the results with someone. You could hand over the spreadsheet and say “here’s what I learned” (not very informative), or you could summarize the data with some charts and graphs that describe the data and communicate some conclusions (e.g. 37% of people said that vanilla is their favorite flavor*). This would sure be easier for someone to interpret than a big spreadsheet. There are hundreds of ways to visualize data, including data tables, pie charts, line charts, etc. That’s the gist of descriptive statistics. Note that the analysis is limited to your data and that you are not extrapolating any conclusions about a full population.
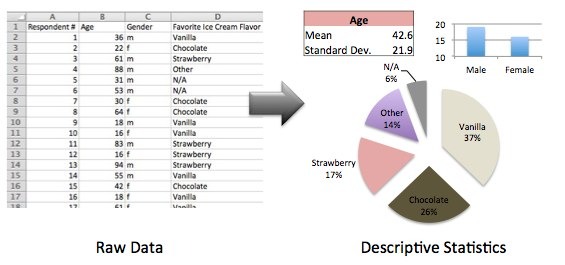
*All data above is completely fictional. I’m not sure how many people actually prefer vanilla. Everyone knows cookies and cream is the best anyway.
Descriptive statistic reports generally include summary data tables (kind of like the age table above), graphics (like the charts above), and text to explain what the charts and tables are showing. For example, I might supplement the data above with the conclusion “vanilla is the most common favorite ice cream among those surveyed.” Just because descriptive statistics don’t draw conclusions about a population doesn’t mean they are not valuable. There are thousands of expensive research reports that do nothing more than descriptive statistics.
Descriptive statistics usually involve measures of central tendency (mean, median, mode) and measures of dispersion (variance, standard deviation, etc.). Here’s a great video that explains the concept of “average” very well.
Inferential Statistics
OK, let’s continue with the the ice cream flavor example. Let’s say you wanted to know the favorite ice cream flavors of everyone in the world. Well, there are about 7 billion people in the world, and it would be impossible to ask every single person about their ice cream preferences. Instead, you would try to sample a representative population of people and then extrapolate your sample results to the entire population. While this process isn’t perfect and it is very difficult to avoid errors, it allows researchers to make well reasoned inferences about the population in question. This is the idea behind inferential statistics.
As you can imagine, getting a representative sample is really important. There are all sorts of sampling strategies, including random sampling. A true random sample means that everyone in the target population has an equal chance of being selected for the sample. Imagine how difficult that would be in the case of the entire world population since not everyone in the world is easily accessible by phone, email, etc. Another key component of proper sampling is the size of the sample. Obviously, the larger the sample size, the better, but there are trade-offs in time and money when it comes to obtaining a large sample. There are some nice calculators online that help determine appropriate sample sizes. That’s enough on market research sampling techniques for now. Let’s get back on track here…
When it comes to inferential statistics, there are generally two forms: estimation statistics and hypothesis testing.
1. Estimation Statistics
“Estimation statistics” is a fancy way of saying that you are estimating population values based on your sample data. Let’s think back to our sample ice cream data. First, let’s assume that we had a true random sample of 35 people on this globe and that our full target population is every human alive (7 billion people). Let’s say that 37% of people in our sample said that vanilla is their favorite flavor. Can we safely extrapolate that 37% of all people in the world also think that vanilla is the best? Is that the true value of the world? Well, we can’t say with 100% confidence, but–using inferential statistical techniques such as the “confidence interval”–I can provide a range of people that prefer vanilla with some level of confidence.
2. Hypothesis Testing
Hypothesis testing is simply another way of drawing conclusions about a population parameter (“parameter” is simply a number, such as a mean, that includes the full population and not just a sample).
With hypothesis testing, one uses a test such as T-Test, Chi-Square, or ANOVA to test whether a hypothesis about the mean is true or not. I’ll leave it at that. Again, the point is that this is an inferential statistic method to reach conclusions about a population, based on a sample set of data.
I hope you now have a solid understand of the differences between descriptive and inferential statistics. If you have any comments or contributions, please leave them in the comments below.
Sources & Additional Resources

Hi thank you for useful info, just curious to know is there any difference between the design of questionnaire in descriptive and inferential research?
can you describe more on dependent and independent variable for both type of research
thank you
I like the way you wrote this like you would have said it. Thanks for the breakdown 🙂
Are tables and graphs examples of descriptive statistics or inferential statistics? ?
does anyone know what Other methods are used to classify different types of statistical analysis rather than descriptive statistics and inferential statistics? The info u explained was great and easy to understand ! Thanks!
thanks for your contribution now i get concept on the data analysis and on how to use them..
Thank U for this useful information.
It really helps
BEST EXPLAINED…
Thanks so much, it was wonderful, now I get the clear concept on data analysis.
Very helpful!
very good explanation
types of statistics
1. descriptive statistics example, tables, charts, graphs
2. inferential statistics examples sample, inductive
3. correlative statistics e.g…………….?
what are the two examples of inductive statistics?
I understood very well. Thanks a lot.
Simple and concise article. Really helped with getting overview.
I love the way you explain everything to my understanding thanks. Now I know and have a very clear and precise difference between Descriptive and inferential statistics
Well explained and practical.
it helps so much. i even lack words to thank you
I have been reading different topics you explained and before that i though i would fail Research Methodology, now i understand many of the things which sounded like chinese on my class notes. Than you very much sir.
Simple and straight to the point. Thank you so much
I really want to thank you for yet another great informative post, I’m a loyal visitor to this blog and I can’t say how much valuable tips I’ve learned from reading your content. I really appreciate all the hard work you put into this great blog.
Excellent explanation . Can’t ask for more ! Thanks a lot !
Best explanation thank you ❤??
Easy quick ?
Amazing explanation with clear examples. thank you
Thank you for your clear and understandable justifications.
Is there correlative statistics? How to show cause and effect relationship? How to get the underlying structure?
Thank you so much
What is exploratory statistics?
I read somewhere that analysis could be descriptive, inferential or exploratory in nature.
Good question. I’ll write an article on it sometime. Exploratory research is intended to help “explore” a question or better understand a problem/topic, rather than answering a specific question. For example, one might ask questions about how people like to get around a city and explore that problem (exploratory), before jumping into questions about what color scooters people like best.