

Primary vs. Secondary Market Research: What’s the Difference?
Market research can be classified as either primary or secondary research. The difference is quite simple, yet there is often confusion around this topic.

In a nutshell, primary research is original research conducted by you (or someone you hire) to collect data specifically for your current objective. You might conduct a survey, run an interview or a focus group, observe behavior, or do an experiment. You are going to be the person who obtains this raw data directly and it will be collected specifically for your current research need. Conversely, secondary research involves searching for existing data that was originally collected by someone else. You might look in journals, libraries, or go to online sources like the US census. You will apply what you find to your personal research problem, but the data you are finding was not originally collected by you, nor was it obtained for the purpose you are using it for. I hope that makes sense. If not, read on for some examples and a little more detail.
Secondary Market Research
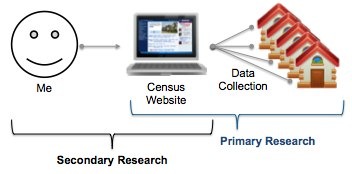
Sometimes called “desk research” (because it can be done from behind a desk), this technique involves research and analysis of existing research and data; hence the name, “secondary research.” Conducting secondary research may not be so glamorous, but it often makes a lot of sense of start here. Why? Well, for one thing, secondary research is often free. Second, data is increasingly available thanks to the Internet; the US Census and the CDC (health data), for example, are two great sources of data that has already been collected by someone else. Your job as a secondary researcher is to seek out these sources, organize and apply the data to your specific project, whether it’s market sizing or segmentation or whatever it may be, and then summarize/visualize it in a way that makes sense to you and your audience. So, that’s what secondary market research is all about. The downside, of course, is that you may not be able to find secondary market research information specific enough (or recent enough) for your objectives. If that’s the case, you’ll need to conduct your own primary research (hey, what a perfect segway!).
Sources of Secondary Data
Secondary data comes in all sorts of shapes and sizes. There are plenty of raw data sources like the US Census, Data.gov, the stock market, and countless others. Internal company data like customer details, sales figures, employee timecards, etc. can also be considered secondary data. Published articles, including peer-reviewed journals, newspapers, magazines, and even blog postings like this count as secondary data sources. Don’t forget legal documents like patents and company annual filings. Social media data is a new source of secondary data. For example, the New York Times collected Twitter traffic during the 2009 Super Bowl and produced this stunning visualization of comments throughout the game. Secondary data is all around us and is more accessible than even. It is increasingly possible to obtain behavioral data from secondary sources, which can be more powerful and reliable than self-reported data (via surveys and focus groups).
Here’s one more incredible example of what can be done with secondary data–this time using publicly available blog posts. The video below is a talk by Jonathan Harris of the “We Feel Fine” project. If you have a moment, check it out.
Primary Market Research
Primary research is research that is conducted by you, or someone you pay to do original research on your behalf. In the case of primary research, you are generating your own data from scratch as opposed to finding other people’s data. You might choose to gather this data by running a survey, interviewing people, observing behavior, or by using some other market research method. Here’s a quick example that explains primary vs. secondary market research.

Both primary and secondary research can be either qualitative or quantitative in nature. I hope this tutorial on the differences between primary and secondary research has been helpful. If I missed something or if you have something to add, please do so with a comment below.


Good info, thoroughly enjoyed it.
I understand very well
I am always with you thank you very much for helping me with this project
I appreciate the information. Thank you.
i appreciate the information. thank you
i understand very well
i understand very well